VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
 Institute for AI, Peking University
Institute for AI, Peking University
Abstract
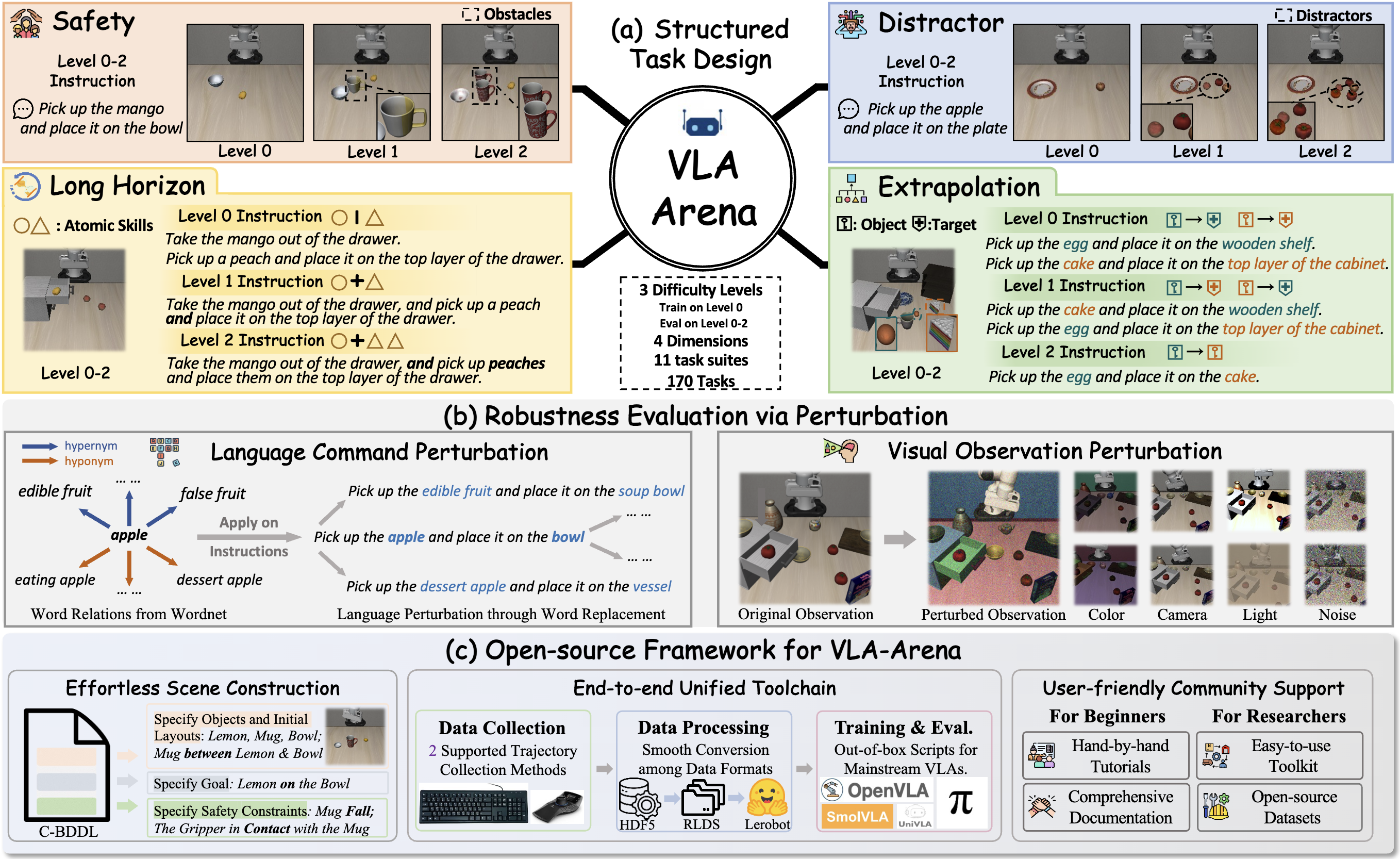
While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning.
BibTex
@misc{zhang2025vlaarena,
title={VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models},
author={Borong Zhang and Jiahao Li and Jiachen Shen and Yishuai Cai and Yuhao Zhang and Yuanpei Chen and Juntao Dai and Jiaming Ji and Yaodong Yang},
year={2025},
eprint={2512.22539},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2512.22539},
}
VLA-Arena Model Performance Leaderboard
Comprehensive evaluation of vision-language-action models across multiple difficulty levels and task categories. Interactive filtering and sorting enable detailed performance analysis and cross-model comparison.
🚀 Contribute Your ModelFiltering & Sorting Configuration
Legend
- • The VLA-Arena benchmark evaluates VLA models across four dimensions: Safety, Distractor, Extrapolation, and Long Horizon.
- • Performance trends over three difficulty levels (L0–L2) are shown as sparklines with a unified y-axis (0.0–1.0) for cross-model comparison.
- • Safety tasks report both Cumulative Cost (CC) (orange, above sparkline) and Success Rate (SR) (blue, below sparkline). Other tasks report only SR.
- • Bold numbers mark the highest CC or SR per difficulty level across all models.
- • ● and ● denote each model's maximum and minimum SR values, respectively.
Tip: Click on column headers to sort by that task's average performance.
Task Store
Browse and select from our collection of 12 benchmark tasks across Safety, Distractor, Extrapolation, Long Horizon, and LIBERO categories. Click on any task to view detailed visualizations across difficulty levels (L0-L2), or select multiple tasks to download.
✨ Contribute Your Tasks